
티스토리 뷰
강화학습 문제는 마르코프 결정 과정(MDP)이라는 수학 체계로 표현할 수 있다.
MDP는 마르코프 체인에 결정과 보상이라는 요소를 추가한 확장판이다.
마르코프란 오직 현재 상태와 행동만 주어질 때, 미래의 상태는 이전의 상태와 독립적이라는 마르코프 성질을 의미합니다.
즉, 미래의 상태를 예측할 수 있다는 의미입니다.
이 성질은 다양한 문제를 단순화할 수 있는 합리적인 가정이다. 이전의 행동에 대해서는 전혀 알 필요가 없는 것이다.
상태란 에이전트의 모든 상태를 나타내는 일련의 표시입니다.
모델(혹은 전이 모델)은 어떠한 상태에서의 행동의 영향을 알려줍니다. 특히, T(S, a, S’)의 T는 S라는 상태에서 a라는 행동을 취해서 S’이라는 상태로 바뀔 때(S와 S’은 같을 수도 있습니다.)의 전이 모델을 뜻합니다. 확률적 행동(비결정적)에서는 확률 P(S’|S,a)를 정의하여 S라는 상태에서 a라는 행동을 취했을 때 S’이라는 상태로 바뀔 확률을 나타냅니다.
행동 a란 가능한 모든 결정들을 의미합니다. a(S)는 S라는 상태에서 취할 수 있는 모든 행동을 의미합니다.
보상이란 어떠한 행동에 대해서 실수의 값을 가지는 반응입니다. R(S)는 S라는 상태에 있을 때의 보상을 뜻합니다. R(S,a)는 S에서 a라는 행동을 취할 때의 보상을 의미합니다. R(S, a, S’)는 S라는 상태에서 a라는 행동을 통해 S’이라는 상태로 끝날 때의 보상을 의미합니다.
정책이란 마르코프 결정 과정의 해답입니다. 정책은 에이전트가 목표를 이루기 위해 취해야 하는 일련의 행동들을 뜻합니다. S라는 상태에서 취해야 하는 행동 a를 나타냅니다. 정책은 π로 나타냅니다. π(s) –> ∞
π* 은 최적 정책, 즉 기대값을 최대로 만드는 정책입니다. 가능한 모든 정책들 중에서 최적 정책은 전체 시간 동안 얻을 수 있는 보상의 기대값을 최대로 만들기 위해 최적화된 정책입니다. MDP에서는 전체 시간이 정해져 있지 않기 때문에 종료 시간을 정해주어야 합니다.
따라서 정책이란 어떠한 상태가 주어졌을 때 어떤 행동을 취해야 하는지 알려주는 지침입니다.
정책은 계획이 아니고, 각각의 상태에 대해서 행동을 반환해서 주어진 환경에 대한 기본적인 계획을 밝혀내는 역할을 합니다.
MDP는 결정 과정에서 행렬을 이용하는 강화학습 접근법입니다. 한 칸은 각각의 상태로 구성되어 있습니다. MDP 과정에서는 주어진 세계를 상태, 행동, 전이 행렬, 그리고 보상으로 나누어 격자 형태로 나타냅니다. 이러한 MDP의 결과로 얻은 해답을 정책이라고 부릅니다. MDP의 목적은 주어진 과제에 대한 최적의 정책을 찾는 것이며 따라서, 상태, 행동, 전이 행렬, 그리고 보상으로 이루어진 마르코프 성질을 따르는 모든 강화학습 문제는 MDP를 이용하여 해결할 수 있습니다.
마르코프 결정 과정 (MDP)은 튜플 (S, A, T, r, γ)로 이루어져 있습니다:
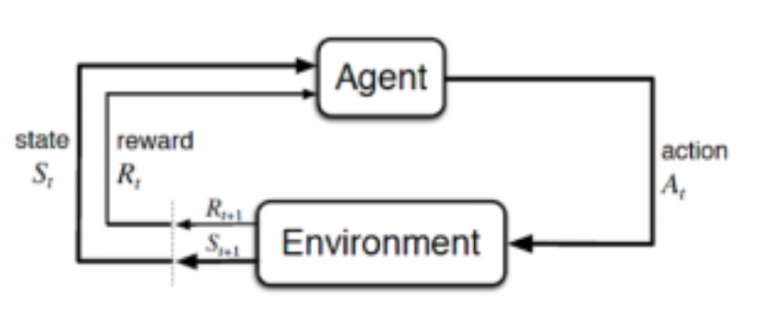
*보상은 에이전트가 어떻게 달성해야 하는지가 아니라 무엇을 달성해야 하는지를 알려줍니다 (출처: Sutton and Barto,2017)
‘S’ 는 일련의 관찰값을 의미합니다. 에이전트는 주변 환경의 상태를 관찰하고 이를 S의 요소로서 추가합니다.
‘A’ 는 일련의 행동을 의미합니다. 에이전트는 이 행동들 중 하나를 선택하여 환경과 상호작용할 수 있습니다.
‘T’ – P(s’ | s, a) 는 전이 확률 행렬을 의미합니다. 이 행렬은 에이전트가 현재 상태 S에서 행동 a를 취했을 때 다음 상태인 S’를 알려줍니다.
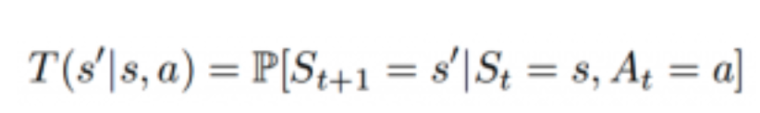
‘r’ – P(r | s, a) 는 현재 상태 S에서 행동 a를 취했을 때 에이전트가 얻을 수 있는 보상을 알려주는 보상 모델을 의미합니다.
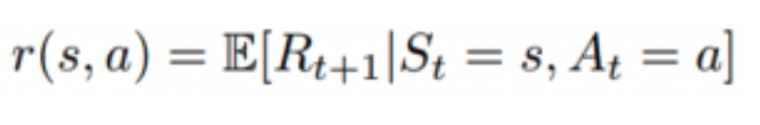
‘γ’ 는 할인 인자를 의미합니다. γ는 현재의 보상과 미래의 보상 사이의 상대적인 중요도를 나타내는 0에서 1 사이 실수의 값을 가집니다. 예를 들면, 만약 에이전트가 어떠한 행동을 취한 즉시 높은 보상을 주고 미래에 더 적은 보상의 기대값을 가지는 상태로 가는 행동과, 직후의 보상은 더 적지만 미래의 보상이 더 큰 행동 중 하나를 고르는 상황에서 할인 인자를 이용합니다.
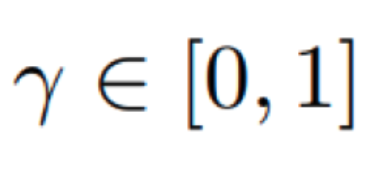
실제 상황에서의 예시:
Roomba라고 불리는 로봇 청소기는 바닥을 청소하는 기계입니다. Roomba는 장애물을 피하면서 청소를 해야하고, 충전기의 위치도 찾아야 합니다. 다음의 네 가지 상태는 로봇이 있을 수 있는 위치를 의미하고, 행동은 어떤 방향으로 움직일지를 의미합니다. 이 로봇은 왼쪽이나 오른쪽으로 움직일 수 있습니다. 첫 번째 상태는 완전히 충전된 상태이고 마지막 상태는 충전 중인 상태입니다. 여기에서의 목표는 어떠한 초기 상태에서도 보상을 최대화하는 최적 정책을 찾는 것입니다.


- 상태는 로봇이 있을 수 있는 위치이고,
- 행동은 가능한 이동 방향으로 나타냅니다.
- 보상은 로봇의 위치에 따라서 +1 혹은 -1
'ML DL Note' 카테고리의 다른 글
| BackPropagation (0) | 2021.08.11 |
|---|---|
| Neural Networks (0) | 2021.08.09 |
| PyTorch (0) | 2021.07.09 |
| Kernel Methods (0) | 2021.07.07 |
| Bayesian Optimization (0) | 2021.07.07 |
- Total
- Today
- Yesterday
- natural language
- EDA
- scikit learn map
- ising model
- kaggle
- opencv
- SeSAC
- spotfire
- ALFFEL
- kinsman
- 머신러닝
- cnn
- Python
- CertifiedAIExpert
- ssac
- CS231
- zfill(x)
- Transfomer
- probablity graph model
- AutoTrading
- 인공지능
- miniSGD
- flask
- BatchNormalization
- Ai
- 시각화
- LeNet
- 대시보드 #정보시각화
- 자본시장 위험 분석 보고서
- #시각화 #데이터시각화 #인포그래픽 #차트 #그래프 #데이터분석 #빅데이터 #시각화툴 #파이썬시각화
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |